Machine learning is an effective tool to use in oncology. By training models on simple phenotypic characteristics, it’s possible to train powerful classifiers for predicting whether or not an individual may have cancer. These kinds of simple classifiers can be used as early detection mechanisms, such that even from a small amount of phenotypic descriptions, doctors can save time by quickly sifting through the probability of a cancer being the root cause of someone’s illness.
Let’s build a quick classifier for lung cancer based on an example Kaggle dataset.
Rows: 309 Columns: 16
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): GENDER, LUNG_CANCER
dbl (14): AGE, SMOKING, YELLOW_FINGERS, ANXIETY, PEER_PRESSURE, CHRONIC DISE...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
skim(df)
Data summary
Name
df
Number of rows
309
Number of columns
16
_______________________
Column type frequency:
character
2
numeric
14
________________________
Group variables
None
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
GENDER
0
1
1
1
0
2
0
LUNG_CANCER
0
1
2
3
0
2
0
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
AGE
0
1
62.67
8.21
21
57
62
69
87
▁▁▆▇▂
SMOKING
0
1
1.56
0.50
1
1
2
2
2
▆▁▁▁▇
YELLOW_FINGERS
0
1
1.57
0.50
1
1
2
2
2
▆▁▁▁▇
ANXIETY
0
1
1.50
0.50
1
1
1
2
2
▇▁▁▁▇
PEER_PRESSURE
0
1
1.50
0.50
1
1
2
2
2
▇▁▁▁▇
CHRONIC DISEASE
0
1
1.50
0.50
1
1
2
2
2
▇▁▁▁▇
FATIGUE
0
1
1.67
0.47
1
1
2
2
2
▃▁▁▁▇
ALLERGY
0
1
1.56
0.50
1
1
2
2
2
▆▁▁▁▇
WHEEZING
0
1
1.56
0.50
1
1
2
2
2
▆▁▁▁▇
ALCOHOL CONSUMING
0
1
1.56
0.50
1
1
2
2
2
▆▁▁▁▇
COUGHING
0
1
1.58
0.49
1
1
2
2
2
▆▁▁▁▇
SHORTNESS OF BREATH
0
1
1.64
0.48
1
1
2
2
2
▅▁▁▁▇
SWALLOWING DIFFICULTY
0
1
1.47
0.50
1
1
1
2
2
▇▁▁▁▇
CHEST PAIN
0
1
1.56
0.50
1
1
2
2
2
▆▁▁▁▇
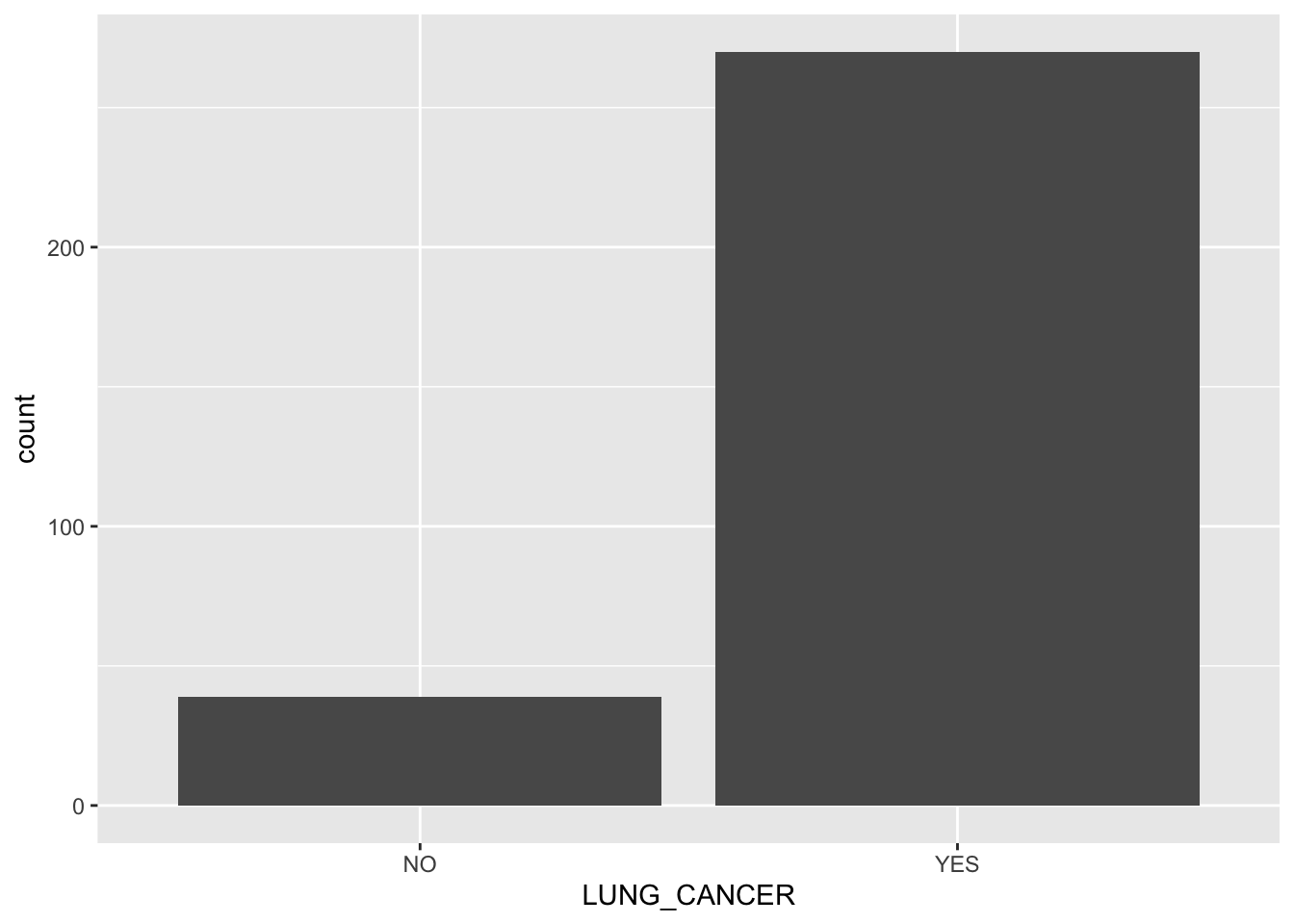
From this, we understand that almost all of the variables are binary “Y|N” questions, with the exception of age. Let’s see the distribution of data:
df %>%ggplot(aes(x=LUNG_CANCER)) +geom_bar()
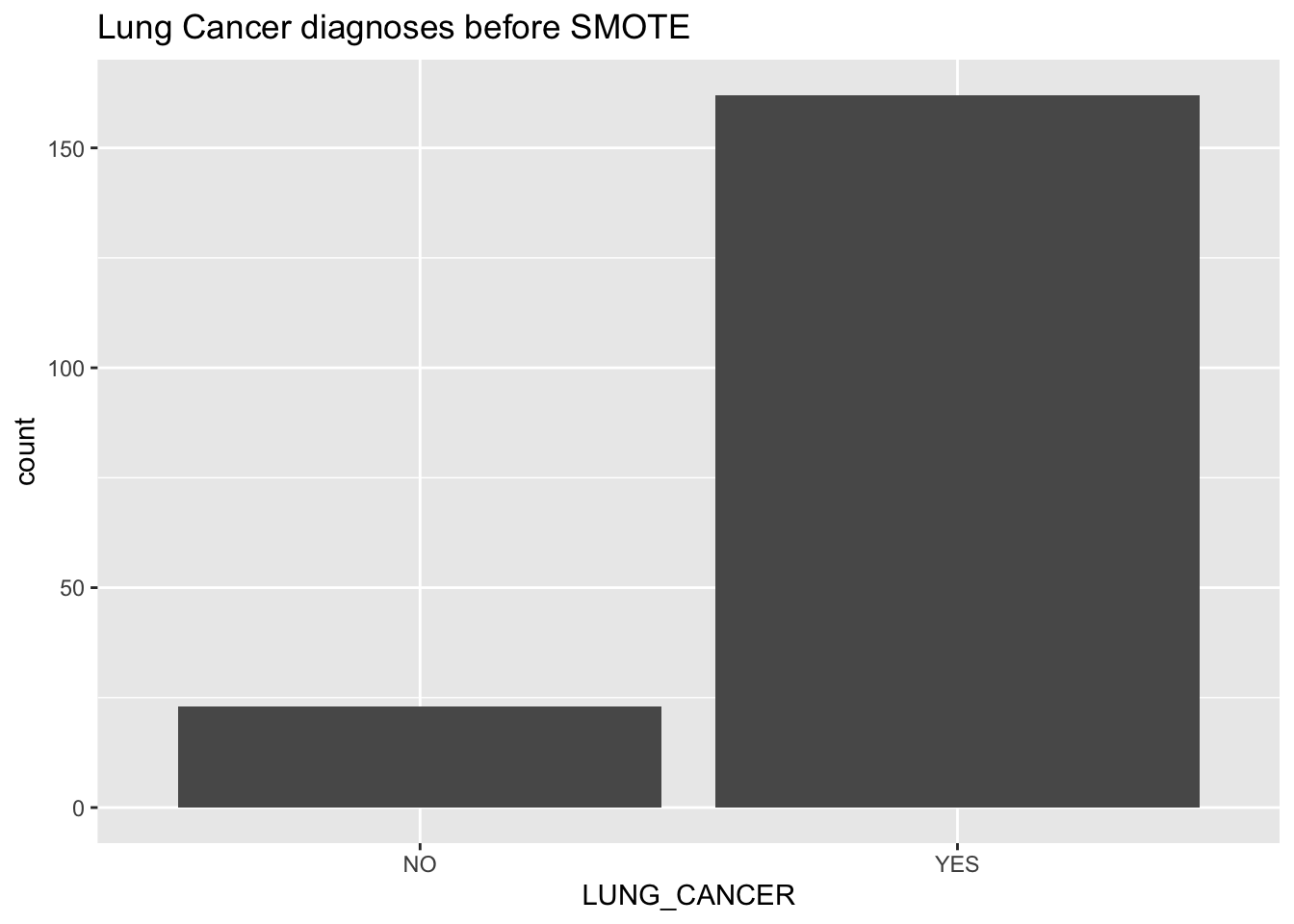
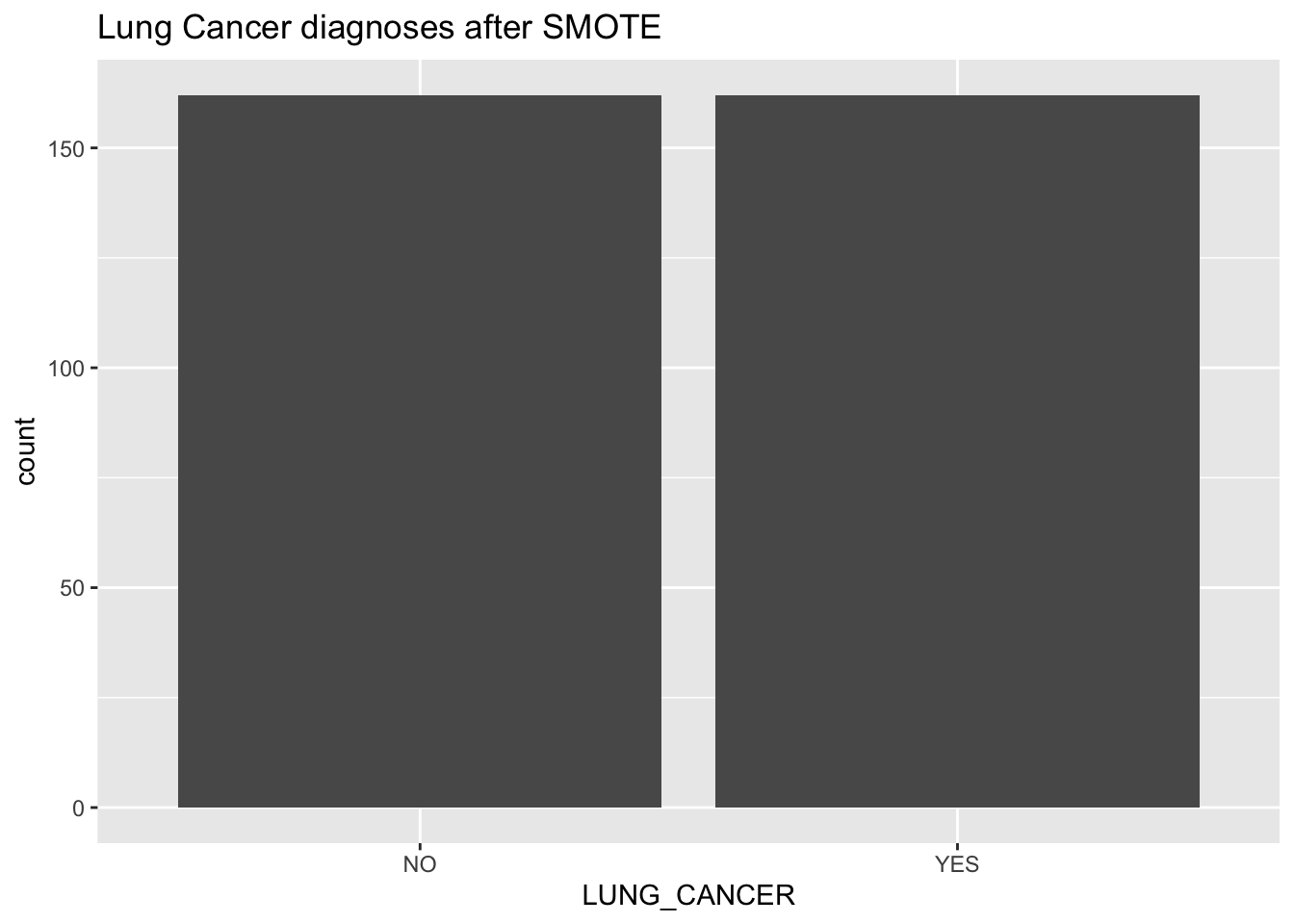
This is imbalanced data for sure, as we can see there are multiple positive cases of lung cancer than negative. We’ll keep this in mind for later. For now, let’s see if there’s any noticeable distribution differences in the two classes:
df %>%group_by(LUNG_CANCER) %>%skim()
Data summary
Name
Piped data
Number of rows
309
Number of columns
16
_______________________
Column type frequency:
character
1
numeric
14
________________________
Group variables
LUNG_CANCER
Variable type: character
skim_variable
LUNG_CANCER
n_missing
complete_rate
min
max
empty
n_unique
whitespace
GENDER
NO
0
1
1
1
0
2
0
GENDER
YES
0
1
1
1
0
2
0
Variable type: numeric
skim_variable
LUNG_CANCER
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
AGE
NO
0
1
60.74
9.63
21
57
61.0
65.5
87
▁▁▇▇▁
AGE
YES
0
1
62.95
7.97
38
58
62.5
69.0
81
▁▃▇▇▂
SMOKING
NO
0
1
1.49
0.51
1
1
1.0
2.0
2
▇▁▁▁▇
SMOKING
YES
0
1
1.57
0.50
1
1
2.0
2.0
2
▆▁▁▁▇
YELLOW_FINGERS
NO
0
1
1.33
0.48
1
1
1.0
2.0
2
▇▁▁▁▃
YELLOW_FINGERS
YES
0
1
1.60
0.49
1
1
2.0
2.0
2
▅▁▁▁▇
ANXIETY
NO
0
1
1.31
0.47
1
1
1.0
2.0
2
▇▁▁▁▃
ANXIETY
YES
0
1
1.53
0.50
1
1
2.0
2.0
2
▇▁▁▁▇
PEER_PRESSURE
NO
0
1
1.26
0.44
1
1
1.0
1.5
2
▇▁▁▁▃
PEER_PRESSURE
YES
0
1
1.54
0.50
1
1
2.0
2.0
2
▇▁▁▁▇
CHRONIC DISEASE
NO
0
1
1.36
0.49
1
1
1.0
2.0
2
▇▁▁▁▅
CHRONIC DISEASE
YES
0
1
1.53
0.50
1
1
2.0
2.0
2
▇▁▁▁▇
FATIGUE
NO
0
1
1.49
0.51
1
1
1.0
2.0
2
▇▁▁▁▇
FATIGUE
YES
0
1
1.70
0.46
1
1
2.0
2.0
2
▃▁▁▁▇
ALLERGY
NO
0
1
1.13
0.34
1
1
1.0
1.0
2
▇▁▁▁▁
ALLERGY
YES
0
1
1.62
0.49
1
1
2.0
2.0
2
▅▁▁▁▇
WHEEZING
NO
0
1
1.23
0.43
1
1
1.0
1.0
2
▇▁▁▁▂
WHEEZING
YES
0
1
1.60
0.49
1
1
2.0
2.0
2
▅▁▁▁▇
ALCOHOL CONSUMING
NO
0
1
1.18
0.39
1
1
1.0
1.0
2
▇▁▁▁▂
ALCOHOL CONSUMING
YES
0
1
1.61
0.49
1
1
2.0
2.0
2
▅▁▁▁▇
COUGHING
NO
0
1
1.26
0.44
1
1
1.0
1.5
2
▇▁▁▁▃
COUGHING
YES
0
1
1.63
0.48
1
1
2.0
2.0
2
▅▁▁▁▇
SHORTNESS OF BREATH
NO
0
1
1.56
0.50
1
1
2.0
2.0
2
▆▁▁▁▇
SHORTNESS OF BREATH
YES
0
1
1.65
0.48
1
1
2.0
2.0
2
▅▁▁▁▇
SWALLOWING DIFFICULTY
NO
0
1
1.13
0.34
1
1
1.0
1.0
2
▇▁▁▁▁
SWALLOWING DIFFICULTY
YES
0
1
1.52
0.50
1
1
2.0
2.0
2
▇▁▁▁▇
CHEST PAIN
NO
0
1
1.31
0.47
1
1
1.0
2.0
2
▇▁▁▁▃
CHEST PAIN
YES
0
1
1.59
0.49
1
1
2.0
2.0
2
▆▁▁▁▇
It looks like fatigue, yellow fingers, allergies, alcohol consumption, and swallowing difficulty are are likely going to be particularly discriminant in differentiating the diagnoses, because they have noticeable imbalance for each case in the histograms.
First Model
Because this is a dataset with a lot of binary decisions, it makes the most sense to use a decision-tree-based model for this data. Additionally, we’re going to use a validation set to test our model so that we don’t commit data leakage.
So even in this small case, we were leaning towards predicting someone without cancer as them having cancer, which is a false positive. Let’s see if we can remedy this at all by tuning some of the random forest parameters:
i Creating pre-processing data to finalize unknown parameter: mtry
Warning: package 'ranger' was built under R version 4.2.3
→ A | warning: While computing binary `precision()`, no predicted events were detected (i.e.
`true_positive + false_positive = 0`).
Precision is undefined in this case, and `NA` will be returned.
Note that 4 true event(s) actually occurred for the problematic event level, NO
There were issues with some computations A: x1
→ B | warning: While computing binary `precision()`, no predicted events were detected (i.e.
`true_positive + false_positive = 0`).
Precision is undefined in this case, and `NA` will be returned.
Note that 1 true event(s) actually occurred for the problematic event level, NO
There were issues with some computations A: x1
→ C | warning: While computing binary `precision()`, no predicted events were detected (i.e.
`true_positive + false_positive = 0`).
Precision is undefined in this case, and `NA` will be returned.
Note that 2 true event(s) actually occurred for the problematic event level, NO
There were issues with some computations A: x1
There were issues with some computations A: x1 B: x2 C: x1
→ D | warning: While computing binary `precision()`, no predicted events were detected (i.e.
`true_positive + false_positive = 0`).
Precision is undefined in this case, and `NA` will be returned.
Note that 3 true event(s) actually occurred for the problematic event level, NO
There were issues with some computations A: x1 B: x2 C: x1
There were issues with some computations A: x1 B: x3 C: x1 D: x1
There were issues with some computations A: x1 B: x4 C: x1 D: x3
There were issues with some computations A: x2 B: x4 C: x1 D: x3
Now let’s look at how the classification metrics over these tuned parameters:
Warning: package 'LiblineaR' was built under R version 4.2.3
→ A | warning: While computing binary `precision()`, no predicted events were detected (i.e.
`true_positive + false_positive = 0`).
Precision is undefined in this case, and `NA` will be returned.
Note that 4 true event(s) actually occurred for the problematic event level, NO
There were issues with some computations A: x1
→ B | warning: While computing binary `precision()`, no predicted events were detected (i.e.
`true_positive + false_positive = 0`).
Precision is undefined in this case, and `NA` will be returned.
Note that 1 true event(s) actually occurred for the problematic event level, NO
There were issues with some computations A: x1
There were issues with some computations A: x1 B: x1
There were issues with some computations A: x1 B: x2
→ C | warning: While computing binary `precision()`, no predicted events were detected (i.e.
`true_positive + false_positive = 0`).
Precision is undefined in this case, and `NA` will be returned.
Note that 2 true event(s) actually occurred for the problematic event level, NO
There were issues with some computations A: x1 B: x2
→ D | warning: While computing binary `precision()`, no predicted events were detected (i.e.
`true_positive + false_positive = 0`).
Precision is undefined in this case, and `NA` will be returned.
Note that 3 true event(s) actually occurred for the problematic event level, NO
There were issues with some computations A: x1 B: x2
There were issues with some computations A: x1 B: x2 C: x1 D: x1
There were issues with some computations A: x1 B: x3 C: x1 D: x2
There were issues with some computations A: x1 B: x4 C: x1 D: x3
There were issues with some computations A: x2 B: x4 C: x1 D: x3
There were issues with some computations A: x2 B: x4 C: x1 D: x3
One of the most important aspects of disease prediction, especially for a disease like cancer, is that your models should ultimately be attempting to reduce harmful errors. In this case, false negatives would be devastating as they can be costly. In this experiment, I found using the F-measure to be a good metric as it let’s us measure not just accuracy, but also the likelihood of making such errors (called Recall in this example).
The final model underperformed in this respect, but I’m sure given some more time, there is an ideal model and parameter set that would reduce false negatives.