An important caveat about understanding cancer is that treatment is not necessarily about “curing” the disease; to summarise Hank Green, a YouTuber who documented his diagnosis and treatment, of the 9000 Americans who develop Hodgkin Lymphoma, 900 die. “Boom, that’s your statistic right there, 10%, right? Nope, not really!”
Survival rates are not designed to be interpreted as simply as that; according to the CDC, such interpretations don’t take into account factors like the age of the individual at time of diagnosis, the duration of the disease, the stage of the cancer, and sophistication of available treatment and technology, and many other factors. Let’s take a look at some data to understand this better.
Patient Journeys
I found a small data set from Our World In Data that we can use to visualize how patients’ journeys are not always the same.
Fetching the Data
We’ll use the data.world package to pull directly from the site and use a short SQL query to check the tables and pull the data into a dataframe:
Warning: package 'readr' was built under R version 4.2.3
Warning: package 'dplyr' was built under R version 4.2.3
Warning: package 'ggrain' was built under R version 4.2.3
Warning: package 'plotly' was built under R version 4.2.3
ds <-"https://data.world/makeovermonday/2018w40-five-year-cancer-survival-rates-in-america"tables <- data.world::query( data.world::qry_sql("SELECT * FROM Tables"),dataset = ds)
Rows: 1 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): tableId, tableName, tableTitle, owner, dataset
lgl (1): tableDescription
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
query <-"SELECT * from five_year_cancer_survival_rates_in_usa"five_yr <- data.world::query( data.world::qry_sql(query),dataset = ds)
Rows: 1887 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): race, gender, cancer_type
dbl (2): survival_rate, year
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
five_yr
# A tibble: 1,887 × 5
survival_rate year race gender cancer_type
<dbl> <dbl> <chr> <chr> <chr>
1 0.559 1977 All races females All cancers
2 0.55 1980 All races females All cancers
3 0.551 1983 All races females All cancers
4 0.576 1986 All races females All cancers
5 0.596 1989 All races females All cancers
6 0.609 1992 All races females All cancers
7 0.618 1995 All races females All cancers
8 0.511 1989 All races males All cancers
9 0.591 1992 All races males All cancers
10 0.608 1995 All races males All cancers
# ℹ 1,877 more rows
From glimpsing this data, we can see that the term “survival rate” can be broken down by race, gender, and cancer type. Essentially, each row tells us what the 5-year survival rate would be that year for a person who contracts that cancer.
Let’s visualize:
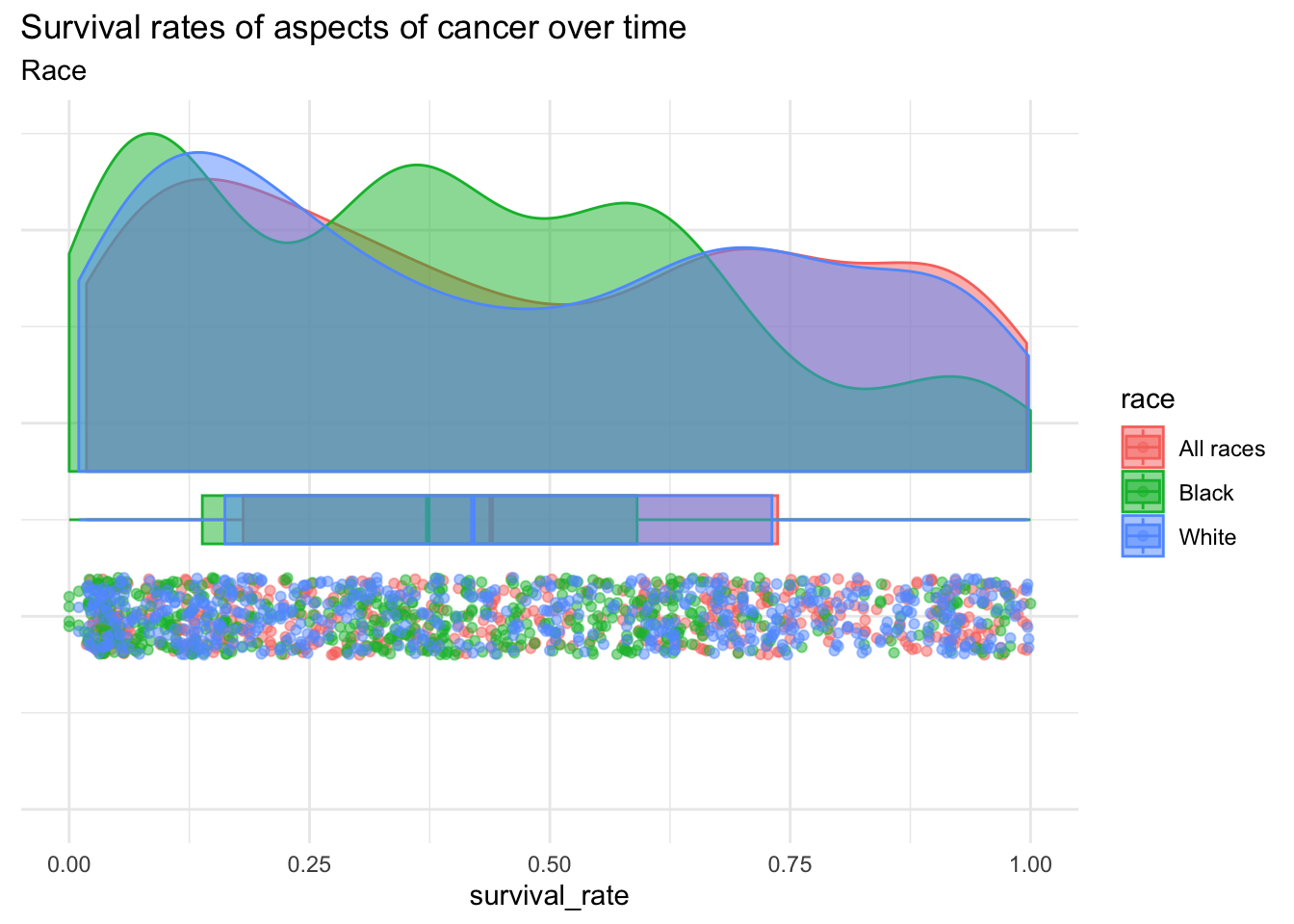
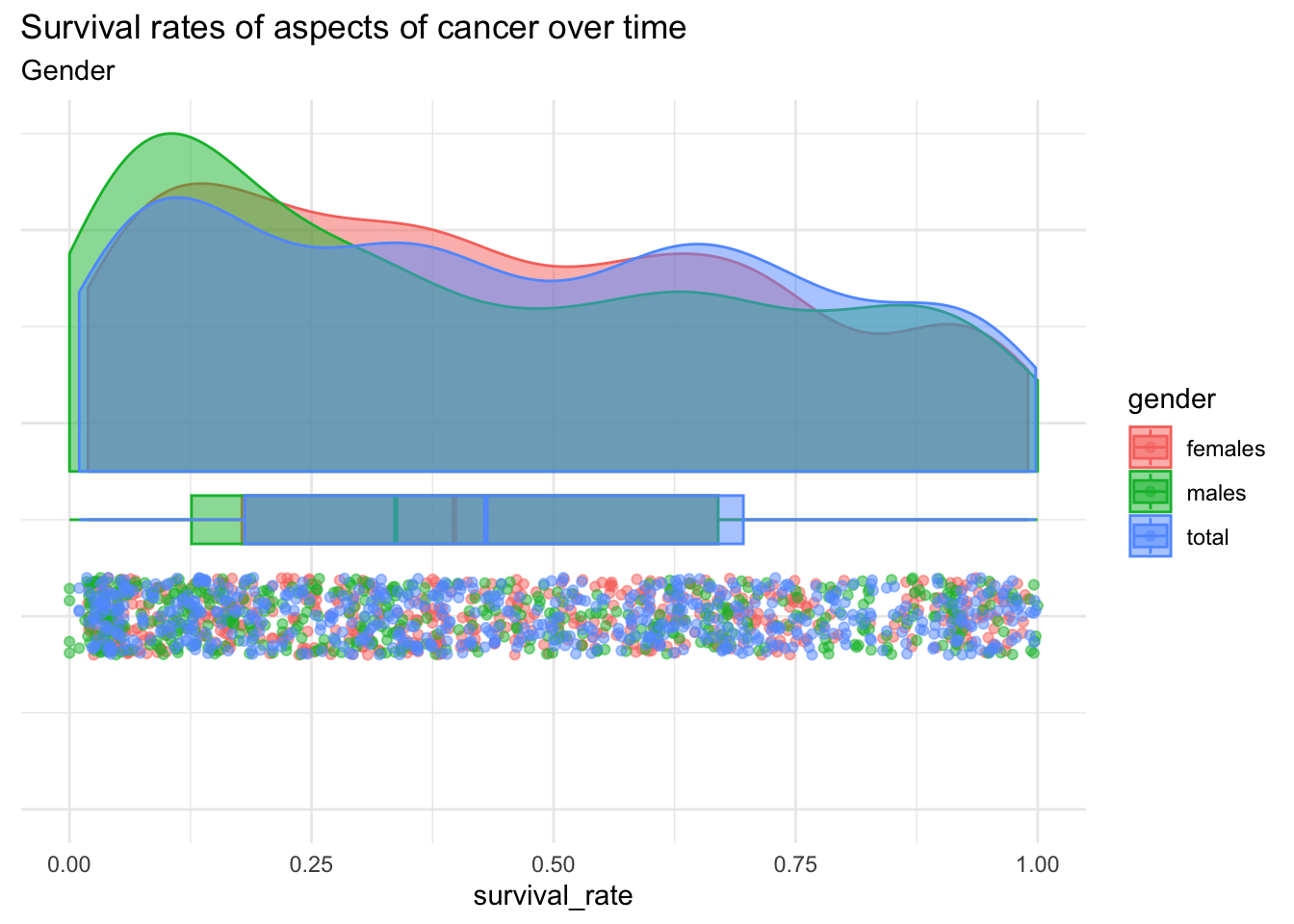
five_yr %>%ggplot(aes(x =1, y = survival_rate, fill = race, colour = race)) +theme_minimal() +geom_rain(alpha = .5) +coord_flip() +theme(axis.text.y =element_blank(), axis.title.y =element_blank())+labs(title ="Survival rates of aspects of cancer over time", subtitle ="Race")
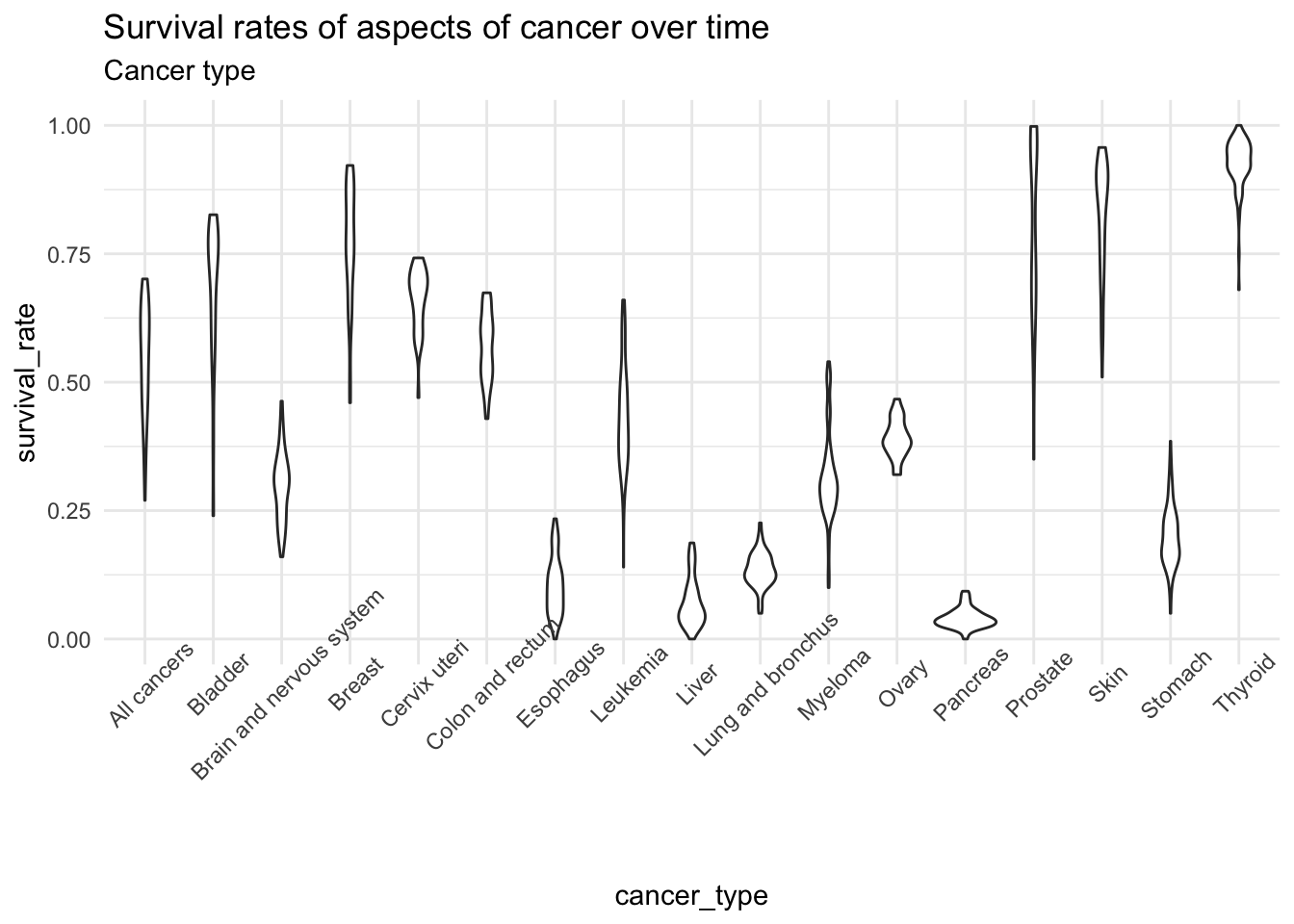
five_yr %>%ggplot(aes(x = cancer_type, y = survival_rate)) +theme_minimal() +geom_violin() +theme(axis.text.x =element_text(angle =45))+labs(title ="Survival rates of aspects of cancer over time", subtitle ="Cancer type")
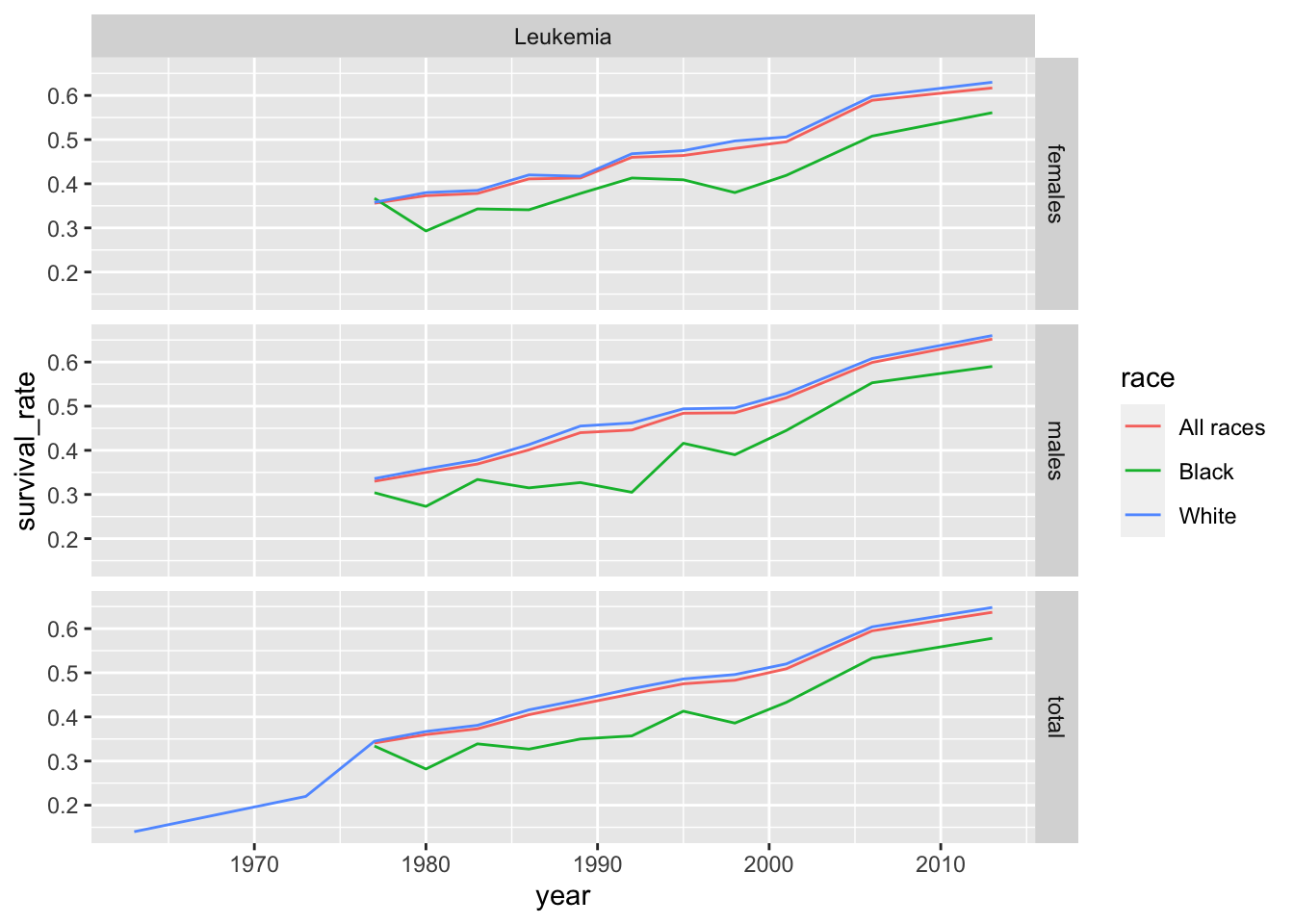
These data appear to be a bit of a mish mosh, but remember that this is over time. Let’s try and put that in perspective by making something similar to the original plot.
This shows an upward trend overall, but there wouldn’t be enough reasonable room to plot each and every combination of variables. We should reasonably compress some of them. I’m going to assume that we wouldn’t be missing out on too much if we ignored intermittent downward trends, so maybe it would be interesting to see the change in survival rate over time?
`summarise()` has grouped output by 'race'. You can override using the
`.groups` argument.
# A tibble: 9 × 3
# Groups: race [3]
race gender survival_rate_change
<chr> <chr> <dbl>
1 All races females 0.261
2 All races males 0.322
3 All races total 0.296
4 Black females 0.194
5 Black males 0.286
6 Black total 0.244
7 White females 0.272
8 White males 0.324
9 White total 0.508
In this table, the percent of people who survive leukemia has increased by the value in the rightmost column. We can think of this as an “improvement in outcomes” measure over time. Let’s do this for all cancers:
`summarise()` has grouped output by 'race', 'gender'. You can override using
the `.groups` argument.
# A tibble: 141 × 4
# Groups: race, gender [9]
race gender cancer_type survival_rate_change
<chr> <chr> <chr> <dbl>
1 Black females Skin -0.146
2 Black males Skin -0.0710
3 All races males All cancers -0.0390
4 All races females Cervix uteri -0.00300
5 All races total Cervix uteri -0.00300
6 Black total All cancers 0.00200
7 Black females Pancreas 0.047
8 All races males Thyroid 0.0510
9 All races males Lung and bronchus 0.055
10 All races males Bladder 0.0550
# ℹ 131 more rows
This is interesting. We can now see that improvement varies by race, gender, and cancer type, with some survival rates actually decreasing over time. That’s worrying. Let’s plot this to see the full gambit:
`summarise()` has grouped output by 'race', 'gender'. You can override using
the `.groups` argument.
pp <- five_yr_change %>%ggplot(aes(y = survival_rate_change, x=cancer_type, fill=gender)) +geom_col(position ="dodge") +coord_flip() +theme_minimal() +facet_grid(~race) +labs(title ="Change in 5-year Survival Rate % of Different Cancers", y ="Survival Rate Change from 1977 to 2013", caption ="The plot shows how the percentage of people who survive 5 years after diagnosis has changed over the last 40 years.")ggplotly(pp)
From this chart, we can conclude that there have been improvements in almost all cancer treatments with a few exceptions — for example, skin cancer amongst black females has seen a noticeable drop in 5-year survival rates. Why would this be?
Conlcusion
This is a quick and dirty look at the data to get a sense of where we are, but overall still speaks to the original comment — understanding survival rates is complicated and all interpretations have to be looked at within their respective contexts.